2: Hvad er data spaces?
Hvad er et data space bygget op af?
En stor del af det arbejde, der indtil videre sker omkring data spaces, handler om at få defineret den overordnede referencearkitektur, der beskriver, hvordan data spaces skal organiseres, hvilke aktørroller der skal indgå i data spaces, efter hvilke fælles spilleregler disse aktører skal interagere, og hvilke overordnede byggeklodser, der skal skabes for at kunne realisere data spaces, der kan leve op til designprincipperne. Selvom de mange forskellige aktører har hver deres måde at visualisere referencearkitekturen og aktørrollerne på – disse ser forskellige ud alt efter, om man tegner et teknisk eller et mere governance-orienteret perspektiv – er det vores oplevelse, at der er relativt stor enighed om de overordnede retningslinjer for data spaces. Hvis man vil forsøge at få et overblik over, hvordan data spaces kan se ud, synes vi, at denne model fra Fraunhofer Institute giver et godt indblik:
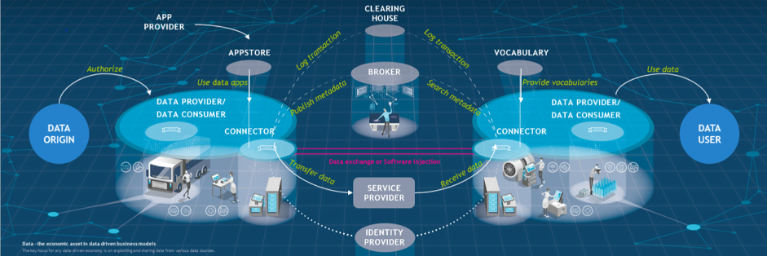
Figur 3: Referencearkitekturmodel fra Fraunhofer Institute
Modellen giver et relativt detaljeret billede af de forskellige aktører og komponenter og indikerer, hvilke transaktioner der skal finde sted mellem de forskellige aktører. Nogle af de vigtigste komponenter, som også går igen i de fleste andre modeller for data spaces, er 'data provider,' 'data consumer,' 'connector,' 'app store,' 'app store provider, 'broker,' 'clearing house,' 'service provider,' 'identity provider,' 'vocabulary provider,' og 'data user.'
Modellens detaljegrad kan dog gøre den svær at forstå for ikke-teknisk-kyndige, og vi har derfor nedenfor forsøgt at lave en simplificeret visualisering af aktørrollerne fra et ikke-teknisk perspektiv. Først skal det dog nævnes, at der stadig er langt fra konsensus om, hvad de forskellige aktørroller kaldes, og hvad de indeholder. Et godt indblik i denne divergens kan ses i Figur 4, hvor Antti Poikola fra Gaia-X Hub i Finland har lavet en oversigt over, hvilke organisationer der bruger hvilke betegnelser for de forskellige aktørroller i et data space:
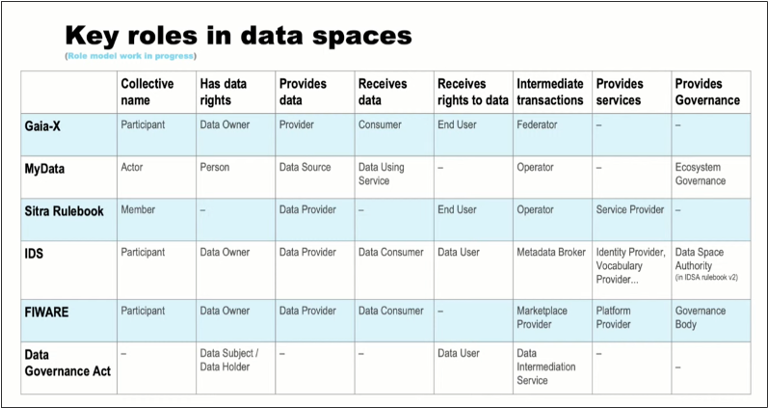
Figur 4: Slide fra Antti Poikola, fra Sitra/Gaia-X Hub Finland, webinar Data Spaces Technology Landscape 2023 (15. december 2022).
Aktørroller i data spaces
I nedenstående model og følgende beskrivelse, har vi forsøgt at komme med et bud på, hvilke begreber der kunne bruges i en dansk sammenhæng, og vi har eksemplificeret dem med velkendte aktører fra energisektoren. Det skal naturligvis understrejes, at dette blot er ét bud, som stadig er til forhandling. Det er dog vores håb, at denne model kan bruges til at åbne en dialog om, hvordan vi italesætter data space-roller i Danmark.
Det skal endvidere nævnes, at det langt fra altid er klart, hvad de forskellige roller indeholder, da de samme aktører sagtens kan indtage flere aktørroller, og deres rolle vil ændre sig, alt efter hvilken interaktion de indgår i.
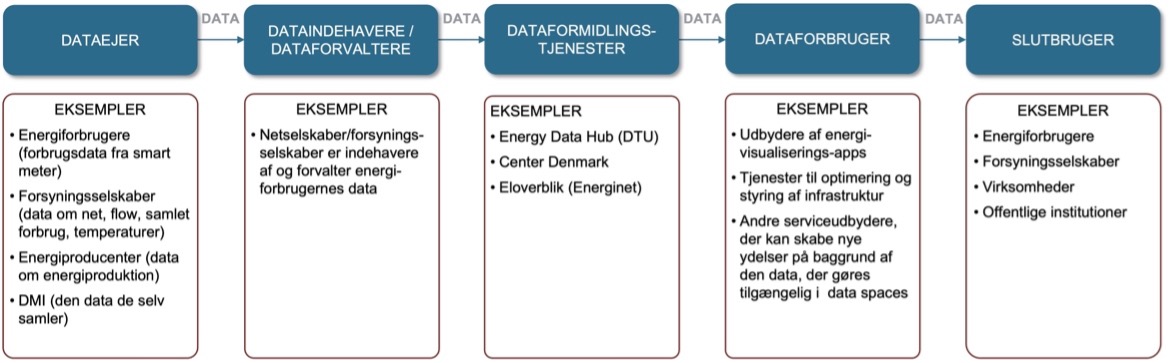
Figur 5: Visualisering af aktørroller i data space-værdikæden fra et ikke-teknisk perspektiv. Udviklet af Alexandra Instituttet i samarbejde med Energinet.
Vi har delt aktørrollerne op i 5 kategorier:
Dataejere ('data owner' på engelsk) betegner den aktør, der har det juridiske ejerskab over data. Alt efter hvilke datakilder der er tale om, kan det være en privatperson, der er dataejer, men det kan også være en juridisk entitet – herunder en virksomhed. Denne aktør er i kontrol over, hvordan data anvendes og behandles af andre aktører i data spacet. Hvis vi bruger eksemplet fra energisektoren, kunne det være forbrugernes forbrugsdata, som indsamles gennem smart meters. Forsyningsselskaber (el, vand, fjernvarme, gas) og netselskaber er også dataejere i form af data om deres elproduktion og data om flow i nettet. Dataejere kan også være virksomheder, der producerer el, rensningsanlæg, Energinets data om elnettet, men også offentligt tilgængelige data som BBR, vejrdata etc.
Dataindehavere eller dataforvaltere (ofte 'data holder' på engelsk) dækker over virksomheder og organisationer, der opbevarer og forvalter data fra kunder/medlemmer, men ikke selv ejer denne data. Det kan både være forsyningsselskaber, netselskaber, fjernvarmeselskaber. Disse aktører er gennem data spaces og eksisterende og ny lovgivning pålagt at gøre de data, de forvalter, tilgængelige for dataejerne, enten gennem deres egne services eller via dataformidlingsservices. Et eksempel herpå er forsyningsselskaber, der er pålagt at gøre deres data tilgængelig for dataejerne igennem Energinets Datahub (se mere nedenfor og i kapitel 6).
Dataformidlingstjenester (ofte 'data intermediary' på engelsk) er virksomheder eller organisationer, der stiller data til rådighed ved at skabe oversigter over, hvilke data der findes indenfor området og giver adgang til dette gennem API'er. Dette er anderledes end de dataforvaltere, der 'blot' formidler de data, de er dataindehavere af, da dataformidlingstjenester har det som deres primære opgave at samle og give adgang til data, der ligger decentralt hos mange forskellige dataejere og dataindehavere. Dataformidlingstjenester kunne være de to aktørroller, der er beskrevet i Data Governance Act som 'dataformidlingstjenester' (kommerciel platform / datamarkedsplatform) og 'dataaltruistiske organisationer' (se afsnit 3.2.2).
Som det vil blive beskrevet, vil disse aktører skulle leve op til nogle krav for at kunne blive godkendte dataformidlere. Nogle af de funktioner, de skal stille til rådighed og leve op til, er, at de skal stille data til rådighed gennem nogle bestemte standarder indenfor den givne sektor, de skal benytte sig af standardiseret vokabular og metadata, de skal gøre det let at søge og finde data på tværs af kategorier og udbydere af data (data broker funktion), og de skal benytte sig af ID-management-funktioner (se eiDAS).
Derudover skal de stille 'intelligente kontrakter' og SLA'er til rådighed, så data kan handles hurtigt og sikkert. Og ikke mindst skal de holde register over, hvem der får adgang til hvilke data og med hvilket formål. I Danmark har vi i energisektoren allerede eksempler på dataformidlingstjenester, som godt nok ikke har bygget deres systemer op omkring data spaces arkitekturen, men som har gjort det til deres kerneforretning/opgave at samle og videreformidle data.
På Energinets Datahub kan markedsaktører fra det danske elmarked finde og få adgang til en lang række datasæt, og ElOverblik gør det muligt for dataejer at få ét samlet overblik over deres elforburg og -produktion samt delegere dataadgang til tredjeparter. DTU (Danmarks Tekniske Universitet) har lavet Energy Data Hub, som samler energidata fra forskellige forskningsprojekter og fra andre frit tilgængelige dataservices og gør denne tilgængelig til forsknings- og innovationsprojekter. Og endelig er Center Denmark en ny aktør (med DTU og en række innovationsorganer og virksomheder som initiativtagere), der har skabt en platform for deling af energidata (læs mere om de danske aktører i kapitel 6).
Dataforbrugeren (ofte 'service provider' på engelsk) er virksomheder, myndigheder, organisationer eller andre aktører, der benytter sig af den data, der gøres tilgængelig gennem dataformidlere til at skabe nye services og derved skabe værdi ovenpå data. Dette kan være kommuner, der udvikler service til borgere, eller det kan være virksomheder, der skaber nye datadrevne produkter og sælger disse til slutbrugere. Siden starten på energikrisen er der sket en eksplosion i sådanne services med de mange nye apps, der skal hjælpe forbrugeren med at følge sit energiforbrug og at forbruge, når strømmen er billig. Men det kan også være virksomheder, der bruger data til at tilbyde nye innovative services til forsyningsselskaber, netselskaber eller rensningsanlæg, så disse kan optimere driften eller som beslutningsstøtteværktøj til udrulning og reparation af infrastruktur. Når der tales meget om, at data spaces skal skabe digital vækst og nye forretningsmodeller, vil det typisk være i denne aktørgruppe.
Slutbrugeren (ofte 'data user' på engelsk) er privatpersoner, virksomheder, myndigheder, organisationer m.m., der bruger et produkt udviklet på baggrund af samkøring af forskellige data fra data spaces. Her bliver det særligt tydeligt, hvordan de samme aktører kan have forskellige aktørroller, da f.eks. netselskabet både vil være dataejer, dataindehaver og slutbruger – og endelig kunne man også godt forestille sig netselskaber, der udvikler nye services på baggrund af data fra data spaces og derved også bliver dataforbruger.
Denne gennemgang er som sagt fra et ikke-teknisk perspektiv og med særligt fokus på aktørrollerne. I det følgende vil vi præsentere en række af de primære byggeklodser, som man forestiller sig, et data space vil bestå af.
Primære byggeklodser til data spaces
I laget under referencearkitekturen, der som sagt optegner de overordnede rammer og spilleregler for, hvem der skal interagere med hvem og hvordan, ligger der en række arkitekturelementer. Disse byggeklodser skal gøre det muligt at interagere på de foreskrevne måder, og de skal sørge for, at data spaces lever op til de overordnede designprincipper omkring suverænitet, distribueret digital troværdighed, en retfærdig spilleplade og en sikker infrastruktur. Hver byggeklods indeholder nogle generiske komponenter, som kan genbruges på tværs af individuelle eller domænespecifikke data spaces, og nogle mere specifikke komponenter, som kan bruges til specifikke formål. Det er ikke nødvendigt for alle data spaces at inkludere alle disse byggeklodser, men listen af byggeklodser giver et godt indblik i, hvilke overvejelser man bør gøre sig, hvis man ønsker at bygge et data space.
Der arbejdes på at få defineret nogle standardiserede krav til disse byggeklodser og på at udvikle nogle certificerede standardkomponenter, som data spaces-aktører kan benytte som skabelon, når de udvikler de endelige softwareløsninger til data spaces-teknologier. Når der er tale om byggeklodser og arkitekturkomponenter, befinder vi os altså stadig på et højere teknologisk abstraktionsniveau og ikke helt nede i den endelig kode og færdige teknologiske softwareløsning.
I Design Principles For Data Spaces findes denne oversigt over de 'byggeklodser', som et data space skal bestå af. Byggeklodserne kan både være tekniske komponenter og governance-elementer:
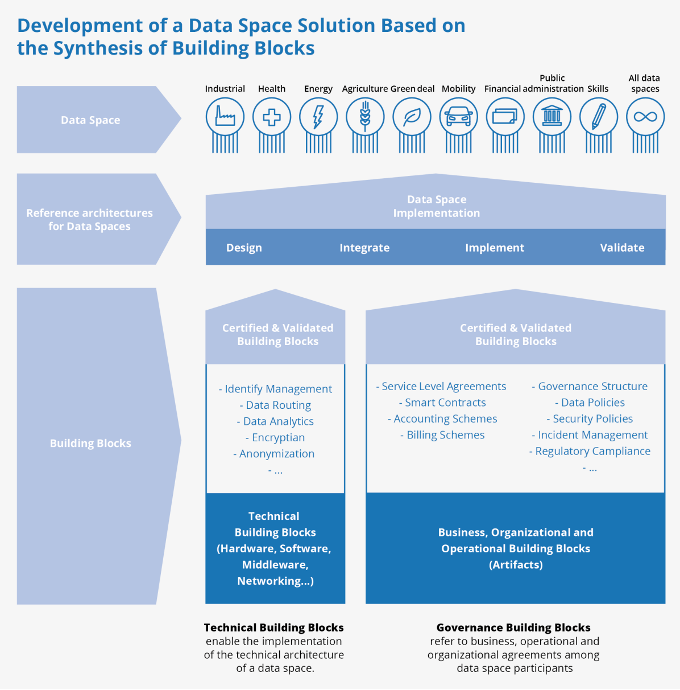
Figur 6: Data space solution based on the synthesis of building blocks. Fra Design Principles for Data Spaces, side 42.
Governance-byggeklodser indeholder de legale, organisatoriske, administrative og forretningsmæssige aftaler, der skal skabe og sikre den værdikæde og de aktører, som er beskrevet ovenfor. Gennem kortlægningen er det blevet klart, at dette vurderes at være den største og sværeste del af arbejdet med at få mobiliseret og realiseret data spaces, da meget af dette handler om organisatoriske strukturer, som skal opfindes og forhandles. Nogle af de byggeklodser, der oftest nævnes, er:
- Forretningsmodeller: At få defineret, hvordan værdi skal skabes og forvaltes på tværs af værdikæden, så alle aktører får værdi af at deltage i data spaces.
- Overordnede samarbejdsaftaler: Dette handler om at skabe standardiserede og verificerbare samarbejdsaftaler gennem definerede Service Level Agreements (SLAer).
- Smarte kontrakter** (smart contracts):** Er maskinlæsbare kontrakter, der definerer brugspolitikker, juridiske aspekter og SLAer på en måde, der er krypteret og sikker.
- Dataevalueringsmetoder: Værktøjer til nemt at validere kvaliteten og oprindelsen af data.
- Kontinuitetsmodel (continuity model): Skal beskriveprocesser for, hvordan man håndterer forandringer, nye teknologier, opdateringer, nye standarder og aftaler i et data space.
- Støttende og juridiske organer: Der er behov for nogle organer, der skal støtte aktører i at lave data spaces, så de lever op til standarderne, og som skal bistå beslutninger, håndhæve reguleringer og afgøre stridigheder. Som beskrevet i næste kapitel (kaptiel 3) er det af EU-Kommissionen besluttet at lave et Data Space Innovation Board, og der er for nylig oprettet et Data Space Support Centre.
Listen over byggeklodser er ikke udtømmende men skal give et indblik i, hvilke komponenter der skal understøtte organiseringen af data spaces.
De tekniske byggeklodser skal desuden sikre, at data space-infrastrukturen kan fungere på tværs af værdikæden, og at der skabes interoperabilitet, tillid og værdi på tværs af data spaces. I Design Principles for Data Spaces optegnes byggeklodserne således:
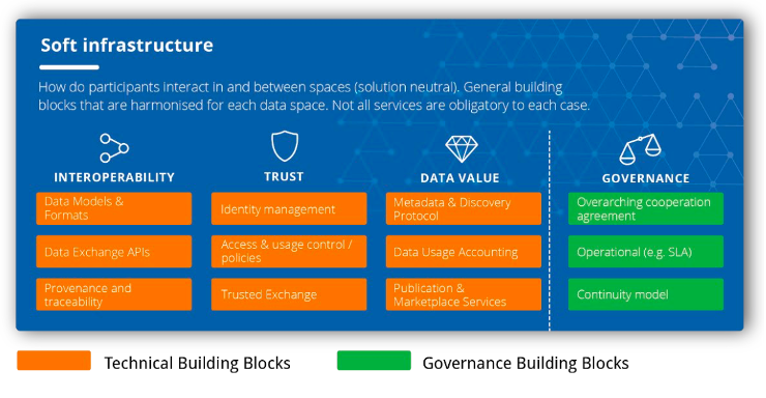
Figur 7: Data space building blocks. Fra Design Principles for Data Spaces, side 44.
De tekniske byggeklodser skal bl.a. skabe det tekniske fundament for interoperabilitet. Interoperabilitet forstås i denne kontekst som én fælles europæisk informations- og interaktionsmodel, der ensretter decentral dataudveksling og -handel på tværs af aktører.
Gennem kortlægningen af hvad de centrale aktører arbejder på (se kapitel 4), fremkommer en liste af arkitekturelementer, som skal være med til opfylde de ovenstående byggeklodskomponenter. Det er ikke vores hensigt at lave en komplet teknologisk forklaring på disse byggeklodser, men hvis man vil forstå, hvad data spaces er bygget op af, kan det være godt med en kort introduktion til, hvad disse begreber dækker over:
- Data space connectors: Skal sikre interoperabilitet på mange niveauer i data spaces. Der arbejdes på en del forskellige 'connectors' (se kapitel 4). Blandt andet er data exchange API'er en absolut essentiel byggeklods i data spaces.
- Identity management: Certificeret software, der skal understøtte distribueret digital troværdighed, så man kan føle sig sikker, når man deler sine data. Identity management skal kunne genkende, godkende og autorisere forskellige enheder (både mennesker og maskiner) i et data space, så man altid kan være sikker på, hvem der har fået adgang til hvilken data. Denne del vil blive bygget i tæt relation med det eksisterende eIDAS ( e lectronic ID entification, A uthentication and trust S ervices).
- Clearing house: Er en generisk back-end logningsservice, der skal holde register over, hvilke data der udveksles mellem hvilke aktører. Som dataformidlingstjeneste vil det være pålagt, at man skal holde register over al datadeling.
- App store: En sikker platform for distribution af data apps.
- Data broker: Standardiserede systemer for at indeksere og søge på data og metadata.
- Vokabular: Et standardiseret vokabular (også kaldet 'ontologies') for data og roller – både på et mere generelt plan og for specifikke domæner. Skal sikre, at data er ensartet struktureret, så man kan samkøre mange typer af data.
De forskellige aktører, der er blevet interviewet til undersøgelsen, har udtrykt enighed om, at udviklingen af de tekniske byggeklodser er den letteste opgave, fordi disse langt hen ad vejen bygger på nogle eksisterende teknologier, som skal tilpasses den overordnede rammearkitektur og krav i data spaces. Et eksempel på dette er digitale tvillinger, der i dag anvendes til at assimilere information fra sensorer ind i nogle afgørende parametre, eksempelvis til at oplyse om spændingsniveauet langs en radial i et DSO-net. Disse data skal kunne tilpasses de tekniske komponenter i data space, så de kan interageres med hinanden.
Som det beskrives mere udførligt i kapitel 4, arbejder mange af de centrale aktører indenfor data spaces på at udvikle generiske og certificerede byggeklodser, som skal gøres tilgængelige, og som data spaces-aktører skal kunne benytte og bygge videre på. Særlig International Data Spaces (IDS), Fraunhofer og Gaia-X arbejder på at udvikle komponenter og certificeringsskemaer, som skal sikre, at man bruger komponenter, der er IDS- eller Gais-X-kompatible (compliant)