2: Hvad er data spaces?
Data spaces er interoperable økosystemer
Data spaces kan forstås som et økosystem af dataøkosystemer, da en af de overordnede visioner er, at der skal skabes en række domænespecifikke data spaces, og at man vil sikre interoperabilitet mellem disse, så data ikke låses fast i domænespecifikke siloer.
Der findes naturligvis allerede mange mere eller mindre formaliserede dataøkosystemer, men det nye i data spaces er, at man – på tværs af offentlige myndigheder, private virksomheder og organisationer – ønsker at blive enige om fælles spilleregler, standarder, overordnede designprincipper, referencearkitektur, fælles arkitekturelementer (tekniske og organisatoriske byggeklodser) og en fælles vedtaget 'governance'-struktur, som man skal inkorporere og leve op til, hvis man vil tage del i data spaces.
En god måde at forstå data spaces på er at tænke på dem som forbundne og interoperable dataøkosystemer, der opererer efter fælles spilleregler.
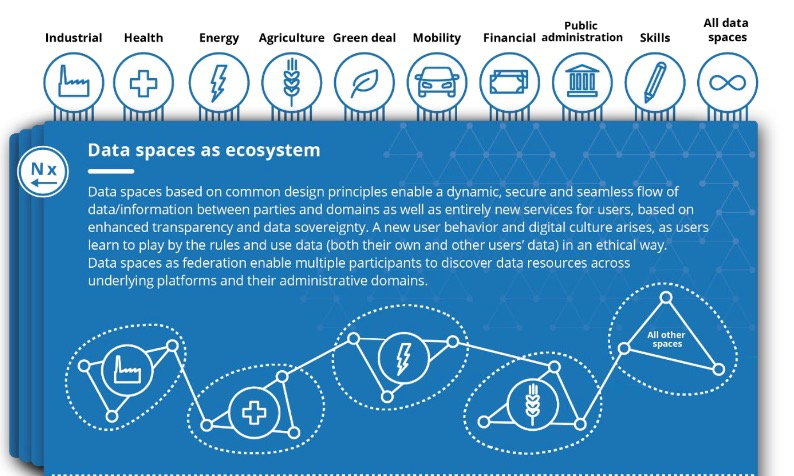
Figur 1: 'Data spaces as ecosystem' fra Design Principles for Data Spaces, side 16. Listen af sektorspecifikke data spaces er ikke endegyldig, og der vil løbende komme nye til. Siden denne illustration blev udarbejdet, er der allerede tilføjet flere sektorer.
Der findes allerede mere eller mindre koordinerede 'data spaces' – eller metoder og systemer for datadeling indenfor forskellige sektorer som f.eks. energi og sundhed, men gennem data spaces vil man hjælpe med at skabe endnu mere enighed om datadeling indenfor de forskellige domæner. Og ekstra vigtigt er det, at der skal skabes fælles standarder og spilleregler på tværs af forskellige domæner, så det bliver lettere at benytte data fra eksempelvis transportsektoren eller fra landbrugssektoren ind i energisektoren. Lige så vigtigt er det, at man skal kunne benytte data på tværs af landegrænser, så man kan sikre international dataudveksling.
As envisioned in the European strategy for data, the different data spaces will be interconnected so that they progressively lead to a genuine European space in which data is broadly shared and used, while fully respecting the rights of individual persons and businesses over data. This will allow the full benefits of data to be reaped for the European economy, society and research. (Commission Staff Working Document on Common European Data Spaces, side 2).
Nøgleordet der skal gøre det muligt at benytte data på tværs af forskellige domæner, aktører og nationer og på tværs af teknologiske komponenter (såsom forskellige IoT-standarder, netværkstyper, cloudteknologier, formater, kodesprog m.m.) er 'interoperabilitet'.
Data spaces er altså det tekniske fundament for interoperabilitet. Interoperabilitet forstås i denne kontekst som én fælles europæisk informations- og interaktionsmodel, der ensretter decentral dataudveksling og -handel på tværs af aktører. Interoperabilitet betyder, at man kan udveksle data på tværs af forskellige systemer, uden at alle systemer skal ensrettes og centraliseres totalt.
Ved at leve op til nogle minimumskrav for, hvordan data skal struktureres og deles, skal det blive muligt at skabe data spaces på tværs af ellers ofte fastlåste datasiloer. Interoperabilitetsdagsordenen er bestemt ikke ny, og data space-dagsordenen bygger således videre på eksisterende og tidligere projekter (f.eks.Minimal Interoperability Mechanisms (MIMs))
Et vigtigt element for at muliggøre datadeling og udnyttelse på tværs af forskellige databaser, teknologier, systemer etc. er de såkaldte 'federated services'. 'Fødererede' kan måske bedst oversættes til 'samlende' services, hvilket vil sige softwareløsninger, der muliggør, at forskelligartede systemer kan benyttes sammen, uden at de forskellige systemer skal ensrettes. Det vil sige, at data i forskellige formater kan samkøres, fordi en fødereret service konverterer dem til fælles modeller og formater.
Ved hjælp af en række fødererede services kan man altså skabe en slags virtuel database, der kan kombinere data fra mange forskellige databaser, dataplatforme, systemer og teknologier og gøre disse mulige at finde, kombinere og anvende (for forklaring af 'data federation' se bl.a. her)
I afsnit 4.2 beskrives nogle af de forskellige 'federated services', som man forestiller sig, at der skal udvikles.
Data spaces er altså ikke afgrænset til én type data men kan bruges til at udveksle flere slags data fra forskellige domæner. Datasæt kan bestå af historiske/stationære data eller være realtid. Nogle datasæt kan være tidsserier (den samme information, som er gentaget over tid, dog opdateret), mens andre er mere statiske og mere eller mindre struktureret. Data kan i øvrigt være simuleringer/forudsigelser om fremtid.
Et data space består af decentraliserede data og teknologiske services, som bindes sammen gennem brug af certificerede og validerede services og fælles besluttede rammer, arkitektur og aftaler. Dette gør data spaces til et alternativt arkitekturdesign ift. på den ene side centraliseret datastyring og på den anden side decentrale datanetværk uden fælles regler og teknologier.
Eksempler på datatyper
- Semistationære data: f.eks. BBR-oplysninger eller data om ledninger og kabler
- Historiske tidsserier af data: f.eks. vejrdata fra tidligere år
- Tidsserier af data: f.eks. forudsigelser af fremtidige energipriser
- Streaming tidsserier af data: f.eks. aktuel luftkvalitet eller energiforbrug/produktion
Det er netop her, at et data space adskiller sig fra dataplatforme eller data lakes, der samler en masse data, og det er også anderledes end datakataloger, der viser vej til en masse forskellige samlinger af data. Med andre ord: dataplatforme, data lakes og datakataloger vil alle udgøre dele af et data space, men de er ikke data spaces i sig selv. Det er interoperabiliteten imellem disse, der skaber data spaces.
"Der er ikke nogen, der ejer et data space, og det er ikke et produkt, man kan købe, hvis blot man har penge nok."
Som Christoph Martens (head of Adaption IDSA) beskriver det på et webinar fra Data Spaces Support Centre (1. dec. 2022) er der ikke nogen, der ejer et data space, og det er ikke et produkt, man kan købe, hvis blot man har penge nok. Data spaces udgøres af et økosystem af decentrale aktører, teknologier og services, og det er netop de fælles spilleregler, standarder, og governancestrukturen, der får data spaces til at hænge sammen og give værdi.

Screenshot fra webinar DSSC Insight Series, 1. Dec. 2022).
En anden grund til at der er behov for en decentral infrastruktur er, at der er tale om så store datamængder, hvor der tilmed kan være behov for deling og aktuering i realtid, at det slet ikke vil være muligt at centralisere data. Det er således ikke kun et spørgsmål om at reducere behovet for centralisering, men i høj grad også at det slet ikke er muligt at centralisere data, hvis data skal bruges til hurtigreagerende aktuering.
Realising interoperable data spaces is more of a coordination challenge: agree on standards and design principles that are accepted by all participants. (Design Principles for Data Spaces, side 8).
Hele projektet med at skabe data spaces kan på mange måder beskrives som en koordineringsøvelse og et standardiseringsarbejde, hvor man skal have skabt de fælles aftalte standarder og principper, som alle aktører og teknologier skal efterleve.
Baseret på disse principper skal der skabes en række teknologiske komponenter/værktøjer, som skal gøre det lettere at dele data på en sikker og troværdig måde, og som skal sikre interoperabilitet på tværs af lande, sektorer og aktører. Nedenfor beskrives først designprincipperne og derefter aktørroller og komponenter. Dette er på mange måder en fragmenteret udvikling, hvor teknologier og rammevilkår skal udvikles samtidigt og i gensidig interaktion med hinanden. Det, der skal binde udviklingen sammen, er de grundprincipper for data spaces, som er vigtige at forstå for at kunne følge udviklingen.